Last Updated on: January 6, 2021 pm
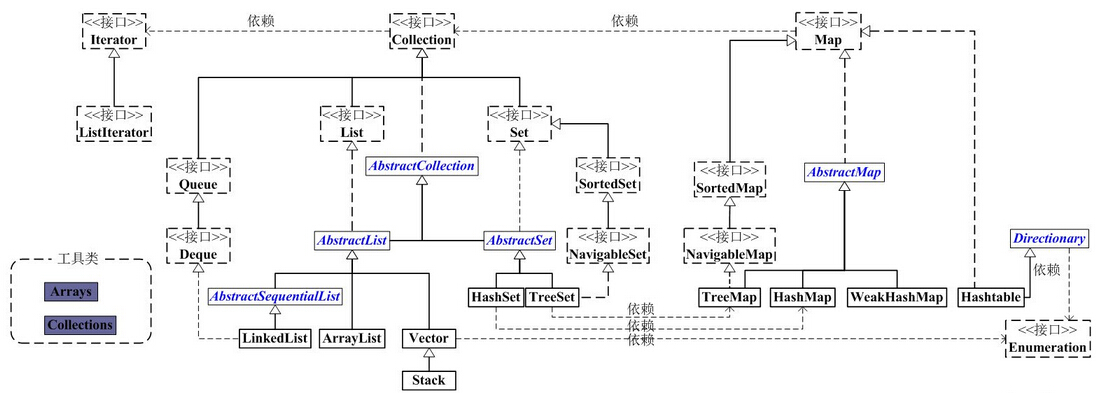
JAVA 集合类 基本概念 JAVA中集合类主要负责保存数据。所有的集合类都位于 java.util 包下。Java容器类类库主要用于保存对象 。主要有两大分支。
Collection —— 容器的每个位置只能保存一个元素。
一组对立的元素。通常Collection中的元素都符合某种规则。
List必须保持一定的顺序。
Set的元素不能重复。
Queue保持队列FIFO原则。
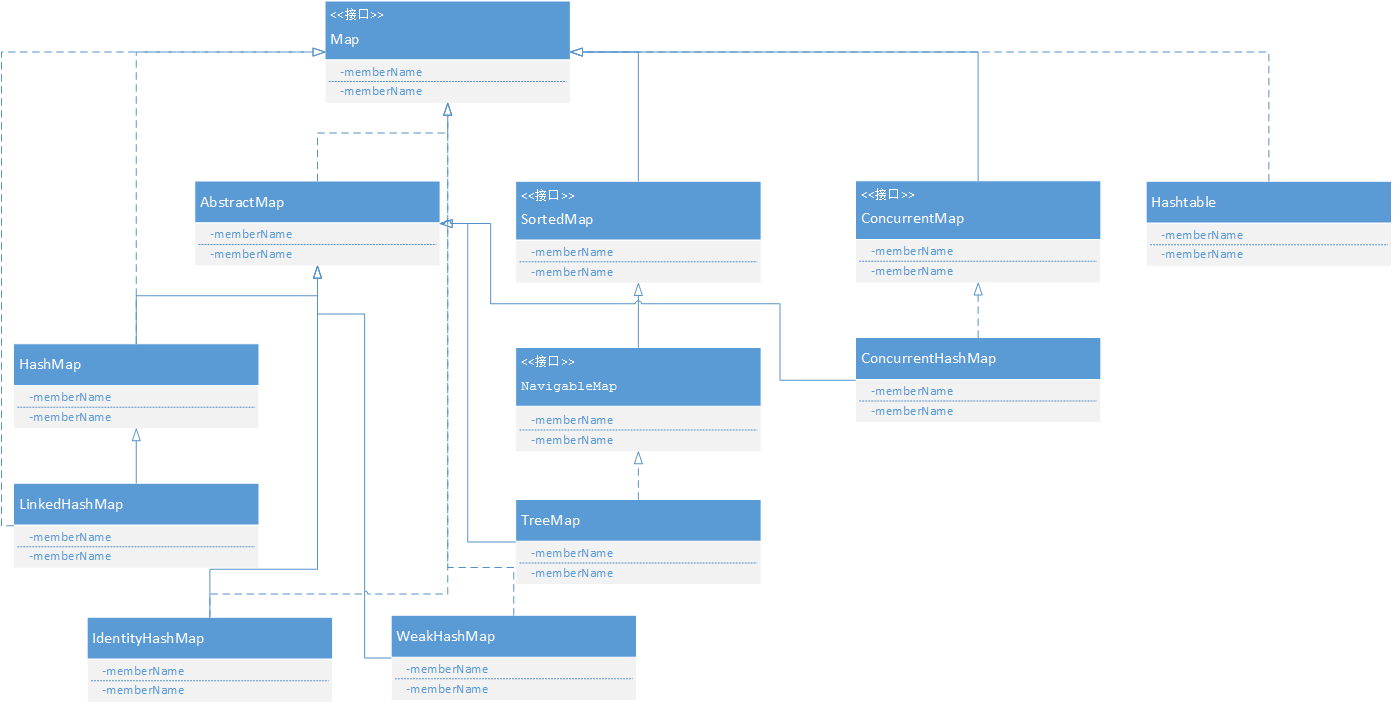
Map —— 容器的每个位置保存一个键值对 ,通过键找到对应的值。
MAP 集合类
Entry类 Map中包含一个内部类Entry。该类中包含了一个key - value 的键值对。其中包含了三个方法。
方法名称
方法解释
getKey()
获取该entry的Key。
getValue()
获取该entry的Value。
setValue()
设置该Entry的Value并且返回新的Value。
Map是一个顶级接口。主要包括几个方法。
覆盖方法 & 更新方法
方法名称
方法解释
equals(Object o)
比较对象和该map是否等价
hashCode()
返回当前map的哈希码
clear()
删除所有映射
remove(Object key)
从Map中删除一堆键值
put(Object key, Object value)
从Map中删除所有映射
putAll(Map t)
将指定Map中所有映射复制到此
返回视图的方法 & 遍历Map
方法名
方法解释
entrySet()
返回Map中所包含的所有映射的Set视图。每一个元素都是Map.Entry对象:可以使用getKey() 和 getValue()的方法访问键和值。
keySet()
返回Map中所有键的Set视图。删除Set中的元素时将会删除Map中相应的映射。
values()
返回Map中所有值的Collection视图。删除Collection中的元素时将会删除Map中相应的映射。
如果要对键值对进行迭代,必须获得一个Iterator对象。
1 2 3 Iterator keyValuePairs = aMap.entrySet().iterator();
访问和测试方法 只检索Map的内容信息但是不更改Map的内容。
方法名
方法解释
get(Object key)
返回与key关联的value
containsKey(Object key)
如果包含指定的key则返回True
containsValue(Obejct value)
如果存在指定的value则返回True
isEmpty()
是否为空
size()
key-value的数目
HashMap 和 Hashtable HASHMAP用的多!!!
不同点
HashMap不是线程安全 的,Hashtable线程安全 —— 通过synchronize实现。
效率:HashMap > Hashtable
HashMap的key可以为NULL,Hashtable不可以。
判断两个Key相同的标准为:两个Key通过equals方法比较后返回True,两个key的HashCode值相等。
LinkedHashMap 它是HashMap的子类,通过双向链表维护键值对的顺序。该双向链表负责维护Map的迭代顺序,与key-value的插入顺序保持一致。
HashMap功能实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 import java.util.*;public class test public static void main (String [] args) new HashMap<Integer, String>();int i = 0 ;101 , "序号 " +200 );while (i < 50 ){"序号 " + i);1 , "序号 " + 199 );200 , "序号 " + 199 );"Traverse 1 :" );for (Map.Entry<Integer, String> entry : hMap.entrySet()){"key : " + entry.getKey() + " , and value : " + entry.getValue());"Traverse 2 : " );while (iterator.hasNext()){"Key: " + entry.getKey() + ", and value: " +entry.getValue());"Traverse 3 : " );for (int key : hMap.keySet()){"Key: " + key + ", and value: " + hMap.get(key));"Traverse 4 : " );while (iter.hasNext()){int key = (int )iter.next();"Key: " + key + ", and value: " + hMap.get(key));public static void sortHashMap (Map<Integer, String> hMap) "按值排序之后:" );new LinkedList<Map.Entry<Integer, String>>(sets);new Comparator<Map.Entry<Integer, String>>() {@Override public int compare (Map.Entry<Integer, String> o1, Map.Entry<Integer, String> o2) return o1.getValue().compareTo(o2.getValue());new LinkedHashMap();for (Map.Entry<Integer, String> entry : linkedList){for (Map.Entry<Integer, String> entry : map.entrySet()){"Key is : " + entry.getKey() + ", and value is : " + entry.getValue());public static void sortHashMapByKEy (Map<Integer, String> hashmap) "按Key排序之后:" );new LinkedList<Map.Entry<Integer, String>>(sets);new Comparator<Map.Entry<Integer, String>>() {@Override public int compare (Map.Entry<Integer, String> o1, Map.Entry<Integer, String> o2) return o1.getKey().compareTo(o2.getKey());new LinkedHashMap();for (Map.Entry<Integer, String> entry : linkedList){for (Map.Entry<Integer, String> entry : map.entrySet()){"Key is : " + entry.getKey() + ", and value is : " + entry.getValue());public static void sortHashMapByTreeMap (Map<Integer, String> hMap) "按键排序之后:" );new TreeMap<Integer, String>(new Comparator<Integer>() {@Override public int compare (Integer o1, Integer o2) return Integer.compare(o1, o2);for (Map.Entry<Integer, String> entry : treeMap.entrySet()){"Key is : " + entry.getKey() + ", and value is : " + entry.getValue());
SortedMap接口和TreeMap实现类 Map接口派生出一个SortedMap子接口,而SortedMap子接口也有一个实现类TreeMap。
TreeMap是一个红黑树结构,对所有的Key进行排序,从而保证TreeMap中所有Key-Value对处于有序状态。
TreeMap有两种排序方法:
自然排序 —— 所有的Key必须实现Comparable接口,而且所有Key应该是同一个类的对象。
定制排序 —— 创建TreeMap时传入一个Comparator对象,负责对TreeMap中所有的Key进行排序。
方法名称
方法解释
Map.Entry firstEntry()
最小key的键值对。
Object firstKey()
最小的Key值。
Map.Entry lastEntry()
最大Key的键值对。
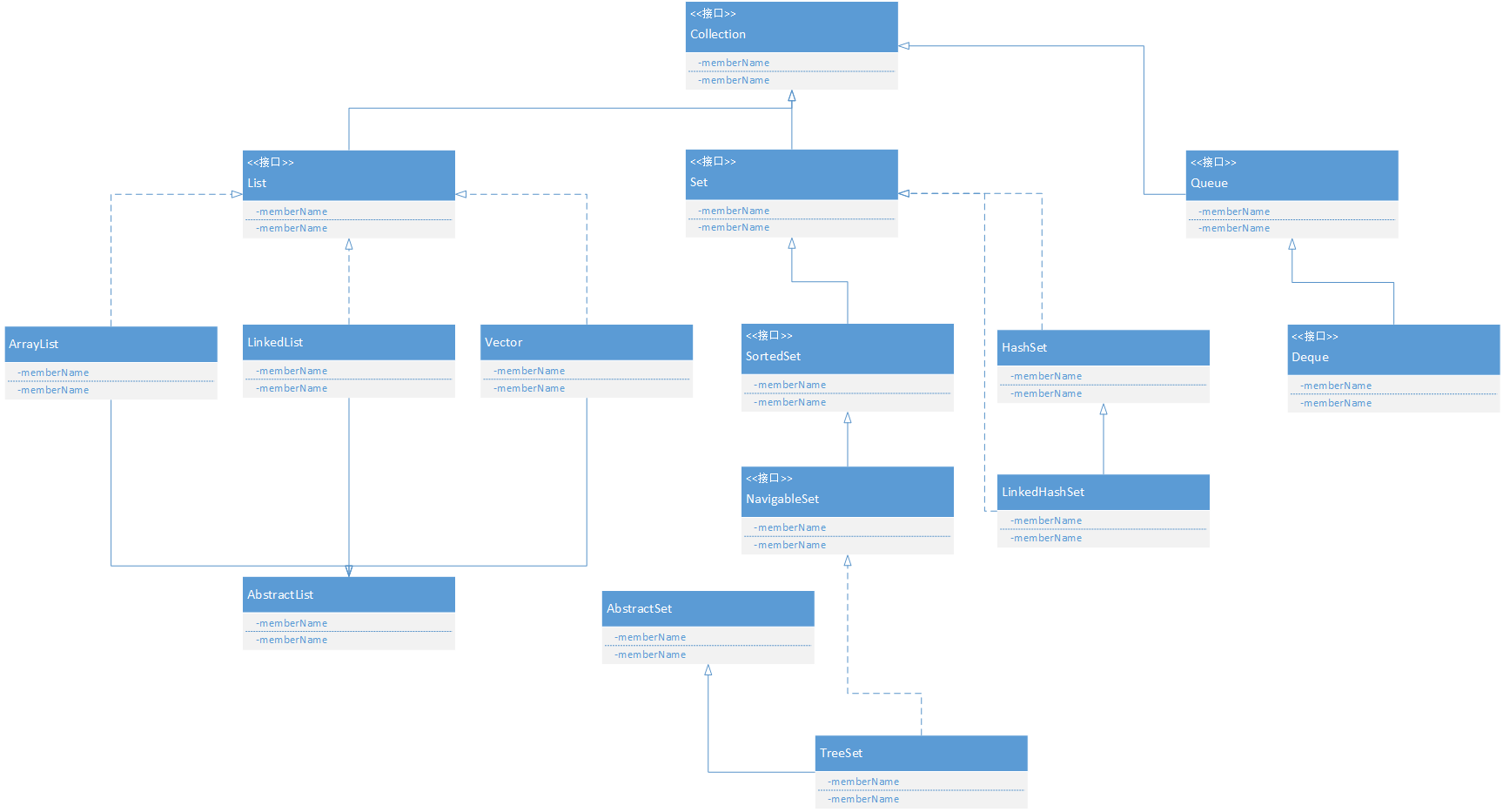
Collection接口及其子类 Collection作为一个集合的根接口,定义了一组对象和它的子类需要实现的方法。
int size() 获取元素个数
boolean isEmpty() 是否个数为 0
boolean contains(Object element) 是否包含指定元素
boolean add(E element) 添加元素,成功时返回 true
boolean remove(Object element) 删除元素,成功时返回 true
Iterator< E > iterator() 获取迭代器
Iterator Collection继承了Iteratable< E >接口,里面只有iterator一个方法,返回一个Iterator迭代器。
1 2 3 4 5 6 7 8 public interface Iterable <T > Iterator<T> iterator () ;
Iterator 的使用方法 遍历集合
1 2 3 4 Iterator iterator = list.iterator();while (iterator.hasNext()){
用Iterator的标准操作方法可以让我们不关心具体集合的类型。使得客户端代码和具体集合类型耦合性弱,复合性更强。但是却点在于无法获得特定元素,只能挨个遍历。
当创建完成指向某个集合或者容器的Iterator对象时,指针其实指向第一个元素的上方。(NULL)
Iterator的主要API
hasNext(): 没有指针下移操作,只判断是否存在下一个元素。
next(): 指针下移,返回该指针所指向的元素。
remove(): 删除当前指针所指向的元素。—— 一般和next方法一起用,这时候作用是删除Next方法返回的元素。
List
List是Collection的一个子接口。
List是一个元素有序的,可以重复并且可以为null的集合。
在Collection集合类中最常使用的几种List实现类为ArrayList, LinkedList, Vector 。
有序&可以重复: List的数据结构是一个序列,存储元素时直接在内存中开辟一块连续的空间,然后将空间与索引对应。
官方文档:
The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
List局部范围操作 List.subList(int fromIndex, int toIndex) 返回的是fromIndex到toIndex之间的子集。注意:左闭右开 —— [fromIndex, toIndex)
subList( ) 返回的是原来List的引用,只是把开始位置offset和size修改了。
由于subList和原来的List保持同一个引用,所以对subList进行操作也会对原来的List产生影响。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.company;import java.util.*;public class ListTest public static void main (String[] args) new ArrayList();7 );8 );9 );10 );11 );0 ,2 );
Output:
1 2 3 4 5 com.company.ListTest7 , 8 , 9 , 10 , 11 ]9 , 10 , 11 ]0
List和Array的区别
相似之处
都可以表示同一类型的对象
使用Index进行索引
不同之处
数组可以存任何类型元素 —— List不能存基本数据类型
数组容量不能改变 —— List容量动态增长
数组效率高 —— List效率相对低一些
总结:当容量固定的时候优先使用数组,容纳的类型更多而且更加高效。
当容量不固定的情况下,用List更有优势(ArrayList & LinkedList)。
ArrayList
ArrayList构造器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public ArrayList () this .elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;public ArrayList (int initialCapacity) if (initialCapacity > 0 ) {this .elementData = new Object[initialCapacity];else if (initialCapacity == 0 ) {this .elementData = EMPTY_ELEMENTDATA;else {throw new IllegalArgumentException("Illegal Capacity: " +public ArrayList (Collection<? extends E> c) if ((size = elementData.length) != 0 ) {if (elementData.getClass() != Object[].class)else {this .elementData = EMPTY_ELEMENTDATA;
ArrayList遍历方式
说明: 遍历效率 —— 索引值 > for循环 > 迭代器
toArray()的使用 通常情况下,调用ArrayList 中的toArray()可能会遇到java.lang.ClassCastException异常。 —— 这是由于 toArray()返回的是Object[]数组,而将Object[]转化为其他类型时会抛出异常,因为其他类型(例如Integer)是Object的子类,而Java不支持向下转型。所以提供了另外一种方法。
<T> T[] toArray(T[] a)
用法如下:
1 2 3 4 5 6 7 8 new Integer[0 ]); new Integer[test.size()];
LinkedList
非线程安全类
双向链表实现
元素时有序的,并且允许元素为null
继承自AbstractSequentialList接口
只有三个成员变量:头结点 First 尾结点 Last 容量 Size
Node是一个双向节点
1 2 3 4 5 6 7 8 9 10 11 private static class Node <E > this .item = element;this .next = next;this .prev = prev;
ArrayList & LinkedList 比较 ArrayList
基于数组,搜索和读取数据很快。
添加和删除元素时效率不高。
每次达到阈值之后需要扩容,有点影响效率。
LinkedList
基于双向链表,添加删除元素效率很高。
只能顺序遍历,所以搜索读取数据效率不高。
没有固定容量不需要扩容。
需要维护链表因此占用空间更多。
Vector
底层由一个可以增长的数组组成
Vector 通过 capacity (容量) 和 capacityIncrement (增长数量) 来尽量少的占用空间
扩容时默认扩大两倍
最好在插入大量元素前增加 vector 容量,那样可以减少重新申请内存的次数
通过 iterator 和 lastIterator 获得的迭代器是 fail-fast 的
通过 elements 获得的老版迭代器 Enumeration 不是 fail-fast 的
同步类,每个方法前都有同步锁 synchronized
在 JDK 2.0 以后,经过优化,Vector 也加入了 Java 集合框架大家族
线程安全!
Queue Set Set 注重元素的独一无二,不能存储重复的元素。并且存储元素时无序 。
Set Implementations
java.util.EnumSet
java.util.HashSet
java.util.LinkedHashSet
java.util.TreeSet
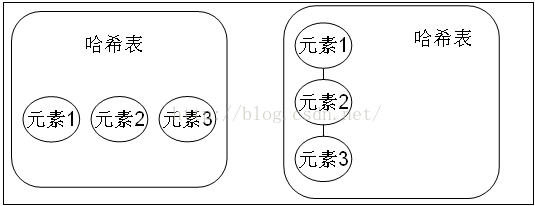
HashSet(SubClass) HashSet中存放的是HashCode,但存储的顺序并不是存入的顺序。
HashSet如何实现不存入重复元素?
通过元素的hashCode() 和 Equals() 方法判断元素是否重复。
如果元素的HashCode是不相同的,那么HashSet会认为对象是不相等的。
然后用Equals()方法比较,如果结果为True,则无法加入。反之可以加入。
那么哈希值HashCode相同的元素如何存储呢?
可以认为相同哈希值的元素放在同一个哈希桶(Bucket)中。
TreeSet(Subclass)